Eestikeelse kõneprosoodia statistiline mudel
(häälikute ja pauside kestused raadiodiktorite kõne
põhjal)
1.
Motivatsioon
Eestikeelne tekst-kõne süntesaator on praegusel kujul vabavarana avalikus kasutuses aastast 2002. Laialdast kasutust ja rakendusi piirab eelkõige väljundkõne monotoonsus, kõne halb sidusus ja ebaloomulik kõla. Kõnesünteesi kitsaskohaks oli ja on kõneprosoodia. See ei ole üksnes eestikeelse kõnesünteesi „pudelikaelaks”, sama probleem on täheldatav enamuse süntesaatorite puhul kogu maailmas. Probleemi lahendust nähakse sidusa kõne korpuste baasil kõneprosoodia modelleerimises.
2. Eesmärk
Raadio- ja teleuudiste sage kuulamine on paratamatult kujundanud meie ettekujutust etteloetava teksti loomuliku kõne mallist. Seetõttu antud projektis keskendutakse raadiodiktorite kõneprosoodia modelleerimisele eesmärgiga kasutada saadud mudeleid eestikeelsel tekst-kõne sünteesil. Erinevate statistiliste prognoosimeetoditega (regressioonanalüüs, regressioonipuud ja närvivõrgud) püütakse modelleerida professionaalsete diktorite kõneprosoodiat, eelkõige kõnerütmi (pausid ja pausieelsed pikendused kõnes) ja kõne ajalist struktuuri (kõneüksuste kestused). Samas kaasati projekti ka eksperte, et nende antud hinnangul korrigeerida sünteesi parameetreid just kõne fraseerimise osas.
3.
Algmaterjal
Lähteandmeteks olid
kõnelõigud (kokku 8 kõnelõiku) pikematest raadiouudistest, mida lugesid
vaheldumisi ette Eesti Raadio mees- ja naisdiktor. Pauside modelleerimisel
kasutati lisaks kõnelõike Andres Otsa poolt etteloetud Rex Stouti kriminullist
„Deemoni surm” ja kõnelõike eesti keele foneetilisest andmebaasist. Kõik kõnelõigud
segmenteeriti häälikuteks ja pausideks.
4. Pauside
analüüs ja modelleerimine
Uudiste kirjalikes üleskirjutustes lasti esmalt uudistelugejate koolitajal (eksperdil) määrata tekstis kohad, kus uudistelugejal tuleks pausid teha. Pausid liigitati kaheks: pausid koos hingamisega ja pausid ilma hingamiseta. Võrreldi reaalsete pauside ilmnemiskohti eksperdi poolt soovitatavatega. Tulemuse põhjal on võimalik reeglistada pauside ja hingetõmmete tekkekohad ja kestused sünteeskõne jaoks uudistelugemise tarbeks. Samuti on võimalik võrrelda eksperdi koostatud reegleid statistilise modelleerimise tulemustega.
Pauside kestuste modelleerimiseks genereeriti teksti põhjal hulk tunnuseid, mis kirjeldasid
- teksti struktuuri (lõigu-, lause- ja fraasilõpp, sidesõna tekstis);
- pausile eelnevat kõnetakti (takti pikkus häälikutes, taktivälde, takti viimase silgi pikkus häälikutes ja binaarne tunnus, mis näitab pausieelset pikendust);
- pausi ajalisi suhteid (kaugus lõigu, lause ja fraasi algusest ning samuti kaugus eelnevast pausist ning eelnevast hingamisest).
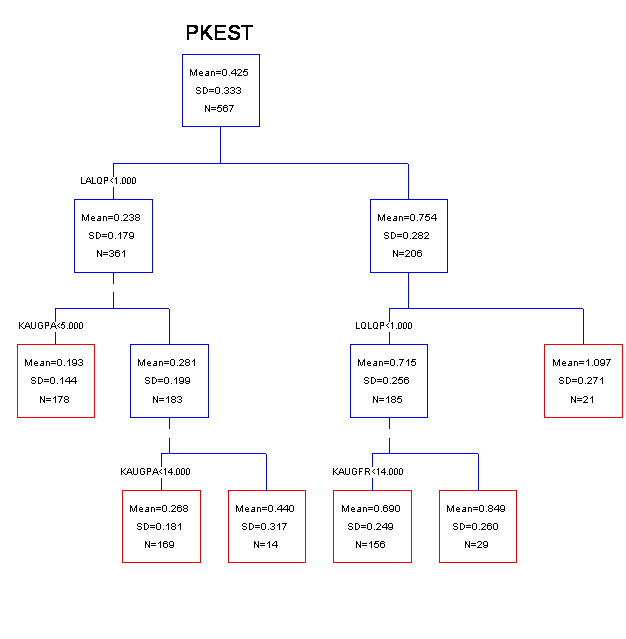
Analüüsiks kasutati statistikaprogrammi SYSTAT 11 ning prognoosimeetoditeks regressioonanalüüsi ja CART meetodit (klassifikatsioon ja regressioonipuud). Modelleerimise käigus osutusid olulisteks tekstistruktuuri tunnustest lõigu-, lause ja fraasilõpp. Pausile eelneva kõnetakti tunnustest osutus oluliseks vaid binaarne tunnus, mis näitas , kas pausile eelnev kõnetakt oli venitatud või mitte. Samuti oli kestuse prognoosimisel oluline konkreetse pausi kaugus talle eelnevast pausist kõnevoos. Joonisel 1 on toodud pausi kestuse arvutusvalem.
Pausi
kestus = 0,098 + 0,369
* LQLQP + 0,470 * LALQP + 0,074 * FRKOM
+ 0,008 * KAUGPA + 0,041 *PIKENDUS
Joonis 1. Võrrand pausi kestuse (sekundites) arvutamiseks tekstis. Muutujad: LQLQP – lõigulõpu tunnus, LALQP – lauselõpu tunnus, FRKOM – fraasilõpp (koma), KAUGPA – kaugus eelmisest pausist, PIKENDUS – viimase kõnetakti pikendus.
Täpsus pausi kestuse prognoosimiseks regressioon analüüsil oli antud materjali põhjal 20,2%. CART meetodil oli prognoosivea protsent pisut kõrgem, küll aga on mudel hästi interpreteeritav (vt joonis 2). Esmane jaotus toimub selle põhjal, kas on tegemist lauselõpu pausiga või mitte. Vasakusse harusse satuvad lausesisesed pausid ja paremasse lauselõpu pausid. Lausesiseste pauside jaotatakse kolmeks: kui eelmine paus oli vähem kui viis kõnetakti tagasi on jooksva pausi kestuseks 0,193 sekundit, kui eelnev paus oli neliteist ja enam takti tagasi on jooksva pausi kestuseks 0,44 sekundit, muudel juhtudel on lausesisese pausi väärtuseks 0,268 sekundit. Analoogiliselt on interpreeteeritav regressioonipuu parem haru, kus fikseeritakse lausete lõpu pausi kestus.
 J
J
Joonis 2. Regressioonipuu pauside kestuste modelleerimiseks tekstis. Muutujad: LQLQP – lõigulõpu tunnus, LALQP – lauselõpu tunnus, KAUGPA – kaugus eelmisest pausist, KAUGFR – kaugus fraasi algusest.
5. Häälikute
kestuste modelleerimine
Sisendandmeteks kestuste statistilisele analüüsile
oli häälikute (foneemide) ja häälikukestuste jada, mis saadi kõnelaine
segmenteerimisel. Kõnele vastava teksti põhjal moodustati tunnuste vektor (17
tunnusega) igale häälikule. Argumenttunnuseid kirjeldati mitmel hierarhilisel
tasandil (foneemi-, silbi-, kõnetakti-, sõna-, fraasi- ja lausetasand). Lähtuti
eeldusest, et igal häälikul on omakestus, häälik kuulub konkreetsesse
häälikuklassi (eesvokaalid, klusiilid, nasaalid, jne), m
- kahendindikaatoreid, selle kohta kas silp/takt/sõna/fraas on viimane/esimene vastavalt taktis/sõnas/fraasis/lauses;
- üleeelmise ning ülejärgmise foneemi klassi ja pikkuse lülitamist tunnuste hulka;
- indikaatorit, kas foneem oli konsonant, vokaal või paus.
Häälikukestuste prognoosimiseks rakendati närvivõrke. Raadiodiktorite andmed jagati enamvähem võrdseks alamhulgaks: närvivõrke treeniti kolme alamhulgaga ja valideeriti neljandaga. Eksperimentidel püüti treenida kahte tüüpi võrke - mitmekihilist pertseptroni ja rekurentset kihilist võrku. Põhiidee seisnes selles, et pertseptron töötleb foneemid ükshaaval, aga rekurentsete võrkude puhul võib grupeerida foneemid silpide, taktide sõnade või fraaside kaupa, ning loota et see annab võrgule eelist (juhul kui see suudab sõltuvusi ära õppida).
Töö käigus valmis hulk utiliite, mille abil saab ainsa koodireaga käivitatakse ühe terve konfiguratsiooni katsetamist ning kõigi tunnuste kohta saab määrata, kas neid kasutada või mitte. Samuti võib anda ette võrgu topoloogia kirjelduse ning grupeerimise infot. Neurovõrkude realisatsioonina kasutati TÜ üliõpilase Mark Fisheli poolt loodud programmipaketti TRNN, mis lubab nii treenida neurovõrke kui rakendada neid hiljem uutele andmetele.
Treenimiskatseid on tehti kokku üle 100. Eksperimentaalsel teel leiti optimaalsed treenimise parameetrid (õppimiskiiruse tegur eta=0.06, inertsitegur alpha=0.6). Samuti valiti edukaima võrgu topoloogiat nii, et testi närvivõrku tunnuseid ühe kaupa eemaldades-lisades.
Parimad tulemused saavutati mitmekihilise pertseptroniga, kui iga foneemi töödeldi eraldi. Keskmine viga testimishulgas oli 18,5%.
Pertseptroni topoloogia sisaldas - sisendkiht 52, peitekiht 26 ja väljundkiht 1 neuroni. Neuroni väljundi funktsiooniks oli 1.7159*tanh(2x/3). Optimaalseks tunnuste komplektiks kujunes: jooksva, eelmise, järgmise ja ülejärgmise foneemi klass ja pikkus ning silbi rõhulisus, silbi tüüp, kõnetakti välde ning viimase silbi indikaator. Väljund normeeriti enne treenimist vahemikku -0,5...0,5 . Joonisel 3 on testivalimi häälikukestuste prognoosi võrdlus originaaliga.
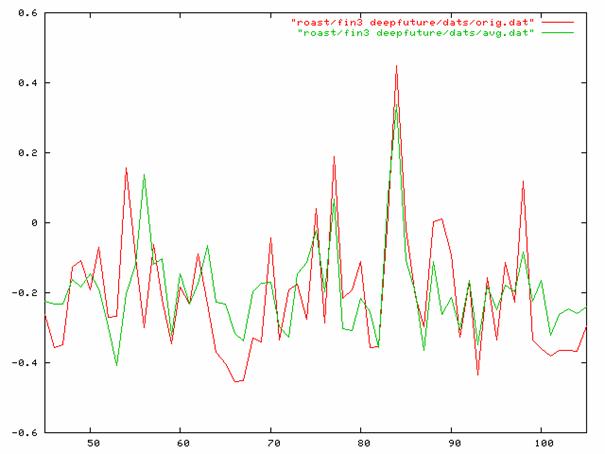
Joonis 3. Häälikukestuste (logaritmitud) prognoosiväärtuste (heledam, roheline joon) võrdlus originaaliga (tumedam, punane joon).
6. Sünteesinäiteid
Praeguse eesti keele kõnesüntesaatori sünteesinäide (reeglipõhine kõneprosoodia)
Statistiliste modelleerimisega alusel genereeritud häälikute ja pauside kestused