Most papers in the field of computational linguistics are orientated to the formalization of syntactic and/or semantic phenomena. Much less attention has been paid to problems connected with word inflection. Yet the morphological analysis -- the recognition of the word initial form (lemma), part of speech and inflection form -- is the basis for the solving of other tasks connected with natural language processing.
Obviously such emphasis is due to the dominant role of English in the field of computational linguistics. The term natural language usually denotes the English language, the morphology of which due to its relative simplicity and paucity of forms does not create special problems in formalization. Mostly all word forms are presented in lexicons together with the necessary information (initial form, grammatical meanings), which reduces morphological analysis just to search in the lexicons. For languages with a complicated morphology such a strategy is not suitable, because it is impossible to keep all word forms in a computer memory.
Automatic morphological synthesis means a system of computer programs to generate all inflectional forms of a word, i.e. to make up a word paradigm. Automatic word-form production is needed in many practical applications of computational linguistics, for instance in language teaching systems, systems supporting linguistic research or editing and translation.
The modelling of word-form generation is also necessary for checking the adequacy of the underlying morphology description.
Agglutination strategy assumes that each word form consists of two smaller units: the stem carrying the lexical meaning, and the formative expressing the complex of grammatical meanings. In the case of a more detailed morphological analysis the formative is further divided into morphemes by different grammatical meanings. The present model is limited to a two-part division. During analysis a word form is divided into units the meanings of which are found in lexicons, whereas in order to make up a word form it is necessary to find the stem and the formative in the lexicons according to their grammatical meanings and then link them to each other.
In the Estonian language both stems and formatives can vary. For example the word pada has three stem variants: pada paja patta, while the formative expressing the present indicative impersonal may have three variants: akse dakse takse. The correct formation of the inflection form requires some information on the mutual suitability of variants. Conditions of the selection of stem and formative variants are described in allotactic rules, which are presented as a morphological classification. The foundation of the present paper is the morphological classification given in Viks 1992: A Concise Morphological Dictionary of Estonian (=MDE). MDE divides the words concerned into 38 inflection types on the basis of the following three features:
1) stem-grade alternation pattern,
2) stem-end alternation pattern,
3) set of formatives for the current
paradigm.
The present model of morphological synthesis consists of three parts:
1) lexicons,
2) rules,
3) automata for rule processing.
From the morphotactical point of view words divide into verbs, nouns and uninflected words. The basic verb paradigm consists of 54 members (compound forms are left out ), while the noun paradigm has 29 members. In addition come the regular parallel forms of the noun.
The model distinguishes between basic
forms and analogy forms. The basic forms are made up according
to allotactic rules given in the type descriptions of the MDE,
whereas analogy forms are obtained from certain basic forms (the
so-called base forms of analogy groups) according to rules
of analogy.
Basic forms of the noun:
1. sg n singular nominative
*2. sg g singular genitive
3. sg p singular partitive
4. sg adt singular aditive
*5. pl g plural genitive
*6. &pl g regular parallel form of plural genitive
(occurrence depends on inflection type)
*7. pl tüvi plural stem
8. pl p plural partitive
9. &pl p regular parallel form of plural partitive
(occurrence depends on inflection
type)
Basic forms of the verb:
*1. sup supine
*2. sup ab supine abessive
3. pts pr ps present participle personal
4. ind ipf sg 3 3rd person singular imperfect indicative
*5. ind ipf sg 1 1st person singular imperfect indicative
*6. ind ipf pl 1 1st person plural imperfect indicative
*7. inf infinitive
*8. imp pr pl 2 2nd person plural present imperative
*9. pts pt ps past participle personal
*10. ind pr sg 3 3rd person singular present indicative
*11. ind pr pl 1 1st person plural present indicative
*12. pts pt ips past participle impersonal
13. ind pr ips present indicative
impersonal
Notes:
-- The base forms of analogy groups are marked by an asterisk (*).
-- Plural stem is not a noun form but
serves only as a base form for regular parallels of plural analogy
forms.
LEXICONS
The lexicons used by this model are
based on MDE, from which three separate parts have been formed:
a lexicon of lemmas, lexicons of stem variants and lexicons of
exceptions. The relevant grammatical information (part of speech,
inflection type, references to parallel types and to morphological
irregularity) is registered in the lexicon of lemmas. All stem
variants are classified into 123 lexicons of stems according to
their inflection type and the kind of stem variant. Irregular
forms are divided between two lexicons of exceptions, one of which
contains the base forms of analogy groups, while the other presents
the single forms.
The lexicon of lemmas has the
lemma as the headword and is structured as follows:
lemma part_of_speech inflection_type
additional_information
As additional information in the lexicon
of lemmas there are references to parallel types (~^?),
to pluralia tantum (#)
and to exceptions(*).
Sample 1.
Lexicon of lemmas
ABERRATSI`OON S 22
ABESS`IINLANE S 10 ?
ABESS`IINLANE S 12 ^
ABESS`IIV S 22
ABU S 17 #
ADV'ERBILINE A 12
J`OOKSLEMA V 30
J`OOKSMA V 32 *
J`AOTIS S 11 ~
J`AOTIS S 09 ~
+JUHATAV A 02
The entry of a stem lexicon
contains two components:
stem_variant reference_to_the_corresponding_lemma
Sample 2. Lexicons of stem variants. Inflection type 6:
a) the strong grade of a lemma stem (06at)
b) the weak grade of a lemma stem (06an)
a)
`AAPE 1
`AATE 4
`AARDE 22b)
AABE 1
AARE 4
AADE 22
The lexicons of exceptions have
the following structure:
reference_to_the_lemma part_of_speech
inflection_type lemma form_code irregular_form
Sample 3. Lexicons of exceptions:
a) irregular base forms of analogy groups
b) irregular single forms
a)
33289 S 26 `ÖÖ ------1G- &ÖÖ[DE
4967 A 26 H`EA ------1-@ H`Ä[I
19845 S 26 P`EA ------1-@ P`Ä[I
3246 P 00 `ENDA ------1-@ `END[I
6763 P 00 ISE ------1-@ `END[I
21061 V 38 P`OOMA -02011--- POO[SIN
21061 V 38 P`OOMA -02041--- POO[SIME
31738 V 38 V`IIMA -02011--- VII[SIN
31738 V 38 V`IIMA -02041--- VII[SIME
b)
27063 S 04 SÜDA ------0P- SÜDANT
10162 S 05 KOHUS ------0P- KOHUT
13460 V 34 L`ASKMA -02031--- &LASI
16274 V 36 MINEMA -02031--- L`ÄKS
Notes:
-- The stem and the formative are separated by '['.
-- The symbol '&' refers to an
irregular parallel form, i.e. an irregular form that does not
replace a regular form but is added to it.
RULES
The allotactic rules describing the synthesis of basic forms are coded as strings, where information related to each word form is separated by the period (.). For instance, the rules necessary for generating the basic forms of words belonging to the inflection types 1, 6, 27, 38 are presented in Sample 4.
After the period in the first position there is a number indicating the stem variant suitable for a certain inflection form, followed by the appropriate formative variant. Zero (0) marks absence of formative, the character '_' indicates a formative fused with the stem, a space in the position of a stem variant marks absence of a corresponding word form.
Sample 4.
Representation of allotactic rules
01:10.10.1T. .1TE. .9I.9ID. .#
06:10.20.1T. .1TE. .2I.2ID. .#
27:1MA.1MATA.1V.1S.1SIN.1SIME.1DA.1GE.1NUD.1B.1ME.1TUD.1TAKSE.#
38: 2MA.1MATA.2V.6_I.6_IN.5_IME.4_A.1GE.1NUD.2B.1ME.2DUD.3AKSE.#
The same principle is used in the generation
of analogy forms (see Sample 5). The number marks the base form,
the stem of which is used in the formation of the following analogy
group. The asterisk (*) indicates the first letter of a variable
formative coinciding with the first letter of the formative of
the corresponding base form of the analogy group.
Sample 5. Representation of analogy rules:
a) noun
b) verb
a)
2.SSE.S.ST.LE.L.LT.KS.NI.NA.TA.GA.D.
5.*ESSE.*ES.*EST.*ELE.*EL.*ELT.*EKS.*ENI.*ENA.*ETA.*EGA.
6.*SSE.*S.*ST.*LE.*L.*LT.*KS.*NI.*NA.*TA.*GA.
7.*SSE.*S.*ST.*LE.*L.*LT.*KS.#
b)
1.VAT.
2.MAS.MAST.MAKS.
5.*ID.*ID.
6.*ITE.
7.*ES.
8.*U.*EM.*U.
9.NUKSIN.NUKSID.NUKS.NUKSIME.NUKSITE.NUKSID.NUKS.NUVAT.
10.N.D...KSIN.KSID.KS.KSIME.KSITE.KSID.KS.
11.TE.VAD.
12.*I.*AKS.*UKS.*AVAT.*UVAT.*AGU.*AMA.*A.*AV.#
AUTOMATA FOR RULE PROCESSING
The process of word form generation
can be described by an abstract automaton, which parses the above-mentioned
strings and behaves according to encountered characters. The possible
actions -- states of the automata are displayed as circles, transitions
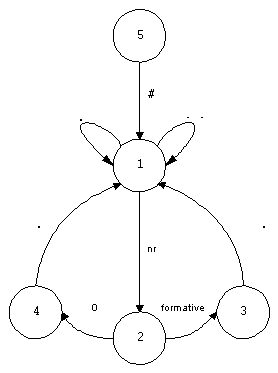
are shown as arcs with conditions upon them. Figure 1 describes
the generation of basic forms, the processing of analogy rules
is shown in Figure 2.
Figure 1.
Generation of basic forms
State 1 is the initial state. The automaton returns to it every time after the period (.) or space (. .) is encountered.
State 2 is reached when an encountered character belongs to numbers. The automaton chooses the stem variant corresponding to the encountered number.
State 3 is reached after reading the formative. The automaton makes up the current basic form by adding the encountered formative to the stem variant found at state 2.
State 4 is reached after reading the character '0'. Current basic form is equal to the stem variant found at state 2.
State 5 is the final state which is reached after encounting the character '#'.
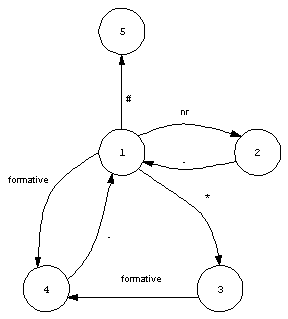
Figure 2.
Generation of analogy forms
State 1 is the initial state. The automaton returns to it every time after the period (.) is encountered.
State 2 is reached when the encountered character belongs to numbers. The automaton finds the stem of the corresponding base form.
State 3 is reached after reading the asterisk (*). The automaton replaces the asterisk with the first character of the formative of the corresponding base form.
State 4 is reached after reading the remaining formative. The automaton makes up the current analogy form by linkig the stem found at state 2 to the formative found at states 3 and 4.
State 5 is the final state which
is reached after encounting the character '#'.
GENERAL ALGORITHM FOR WORD FORM PRODUCTION
1. Retrieve the grammatical information (part of speech, inflection type) and references to the exceptions and parallel types from the lexicon of lemmas.
2. Retrieve the stem variants corresponding to the lemma and the inflection type from lexicons of stem variants.
3. Make up the basic forms according to allotactic rules.
4. In the case of reference to exceptions retrieve and replace the irregular base forms of analogy groups (if available in the lexicon of exceptions).
5. Make up the remained members of the paradigm by rules of analogy.
6. In the case of reference to exceptions
retrieve and replace the irregular single forms (if they occur
in the lexicon of exceptions).
Sample 6.
Generation of the paradigm for the word süda \heart\
1. The entry for the word süda in the lexicon of lemmas
SÜDA S 04 *
indicates that this word belongs to
nouns from the inflection type 4 and has some irregular forms.
2. Lexicons of stem variants give two possible stem variants:
SÜDA
SÜDAME
3. According to the allotactic rules for the inflection type 4 the following basic forms are made up (see Sample 4 and Figure 1):
1. sg n SÜDA
*2. sg g SÜDAME
3. sg p SÜDAT
4. sg adt
*5. pl g SÜDAMETE
*6. &pl g
*7. pl tüvi SÜDAMEI
8. pl p SÜDAMEID
9. &pl p
4. There are no irregular base forms
of analogy groups in the lexicon of exceptions.
5. The analogy forms are made up according
to the analogy rules (see Sample 5 and Figure 2).
6. The irregular single form -- singular
partitive is retrieved and replaced: SÜDAT
®
SÜDANT.
Final result:
sg n SÜDA
sg g SÜDAME
sg p SÜDANT
sg adt
pl g SÜDAMETE
pl p SÜDAMEID
sg ill SÜDAMESSE
sg in SÜDAMES
sg el SÜDAMEST
sg all SÜDAMELE
sg ad SÜDAMEL
sg abl SÜDAMELT
sg tr SÜDAMEKS
sg ter SÜDAMENI
sg es SÜDAMENA
sg ab SÜDAMETA
sg kom SÜDAMEGA
pl n SÜDAMED
pl ill SÜDAMETESSE & SÜDAMEISSE
pl in SÜDAMETES & SÜDAMEIS
pl el SÜDAMETEST & SÜDAMEIST
pl all SÜDAMETELE & SÜDAMEILE
pl ad SÜDAMETEL & SÜDAMEIL
pl abl SÜDAMETELT & SÜDAMEILT
pl tr SÜDAMETEKS & SÜDAMEIKS
pl ter SÜDAMETENI
pl es SÜDAMETENA
pl ab SÜDAMETETA
pl kom SÜDAMETEGA
Sample 7.
Generation of the paradigm for the word pooma \ to hang\
1. The entry for the word pooma in the lexicon of lemmas
P`OOMA V 38 *
indicates that this word belongs to
the verb class from the inflection type 38 and has some irregular
forms.
2. Lexicons of stem variants give six possible stem variants:
P`OO POO P`UU PUU
P`Õ PÕ
3. According to the allotactic rules
for the inflection type 38 the following basic forms are made
up (see Sample 4 and Figure 1):
*1. sup P`OOMA
*2. sup ab POOMATA
3. pts pr ps P`OOV
4. ind ipf sg 3 P`ÕI
*5. ind ipf sg 1 P`ÕIN
*6. ind ipf pl 1 PÕIME
*7. inf P`UUA
*8. imp pr pl 2 POOGE
*9. pts pt ps POONUD
*10. ind pr sg 3 P`OOB
*11. ind pr pl 1 POOME
*12. pts pt ips P`OODUD
13. ind pr ips PUUAKSE
4. The irregular base forms of analogy groups are replaced:
P`ÕI ®
P`OOS P`ÕIN ®
POOSIN PÕIME ®
POOSIME
5. The analogy forms are synthesized
according to the analogy rules (see Sample 5 and Figure 2).
6. There are no irregular single forms in the lexicon of exceptions.
Final result:
sup P`OOMA
sup ab POOMATA
pts pr ps P`OOV
ind ipf sg 3 P`OOS
ind ipf sg 1 POOSIN
ind ipf pl 1 POOSIME
inf P`UUA
imp pr pl 2 POOGE
pts pt ps POONUD
ind pr sg 3 P`OOB
ind pr pl 1 POOME
pts pt ips P`OODUD
ind pr ips PUUAKSE
kvt pr ps P`OOVAT
sup in POOMAS
sup el POOMAST
sup tr POOMAKS
ind ipf sg 2 POOSID
ind ipf pl 3 POOSID
inf ipf pl 2 POOSITE
ger P `UUES
imp pr sg 3 POOGU
imp pr pl 1 POOGEM
imp pr pl 3 POOGU
knd pt sg 1 POONUKSIN
knd pt sg 2 POONUKSID
knd pt sg 3 POONUKS
knd pt pl 1 POONUKSIME
knd pt pl 2 POONUKSITE
knd pt pl 3 POONUKSID
knd pt ps POONUKS
kvt pt ps POONUVAT
ind pr sg 1 P`OON
ind pr sg 2 P`OOD
ind pr ps (neg) P`OO
imp pr sg 2 P`OO
knd pr sg 1 P`OOKSIN
knd pr sg 2 P`OOKSID
knd pr sg 3 P`OOKS
knd pr pl 1 P`OOKSIME
knd pr pl 2 P`OOKSITE
knd pr pl 3 P`OOKSID
knd pr ps P`OOKS
ind pr pl 2 POOTE
ind pr pl 3 POOVAD
ind ipf ips P`OODI
knd pr ips P`OODAKS
knd pt ips P`OODUKS
kvt pr ips P`OODAVAT
kvt pt ips P`OODUVAT
imp pr ips P`OODAGU
sup ips P`OODAMA
ind pr ips (neg) P`OODA
pts pr ips P`OODAV
The computer program created to test the present model of synthesis works in dialog or file-to-file mode and generates either the whole paradigm, basic forms or certain forms according to the user's selection.
The system of the lexicons, data retrieval
units and the rule component are common both to the synthesis
and analysis programs.